
Want to understand customer intent across languages? Here’s what you need to know:
• Cross-lingual intent detection helps AI grasp user needs in multiple languages • It’s crucial for global businesses using chatbots and virtual assistants • 81% of companies struggle with multilingual AI data
Top 5 methods in 2024:
- Multilingual Sentence Encoders (LaBSE)
- Cross-Language Transfer Learning
- Zero-Shot Learning with Large Language Models
- Machine Translation-Based Approaches
- Hybrid Models
Quick comparison:
| Method | Pros | Cons |
|---|---|---|
| LaBSE | Works for rare languages, good at zero-shot | Needs lots of computing power |
| Transfer Learning | Uses knowledge from major languages | Results vary by language similarity |
| Zero-Shot LLMs | No task-specific data needed | Limited to 5-8 classes without fine-tuning |
| Machine Translation | Works with any language pair | Translation errors affect accuracy |
| Hybrid | More accurate and relevant | Complex setup |
Key takeaway: Choose based on your needs and resources. Smaller models like Flan-T5-Base can be cost-effective for many tasks.
Related video from YouTube
Multilingual Sentence Encoders (LaBSE)
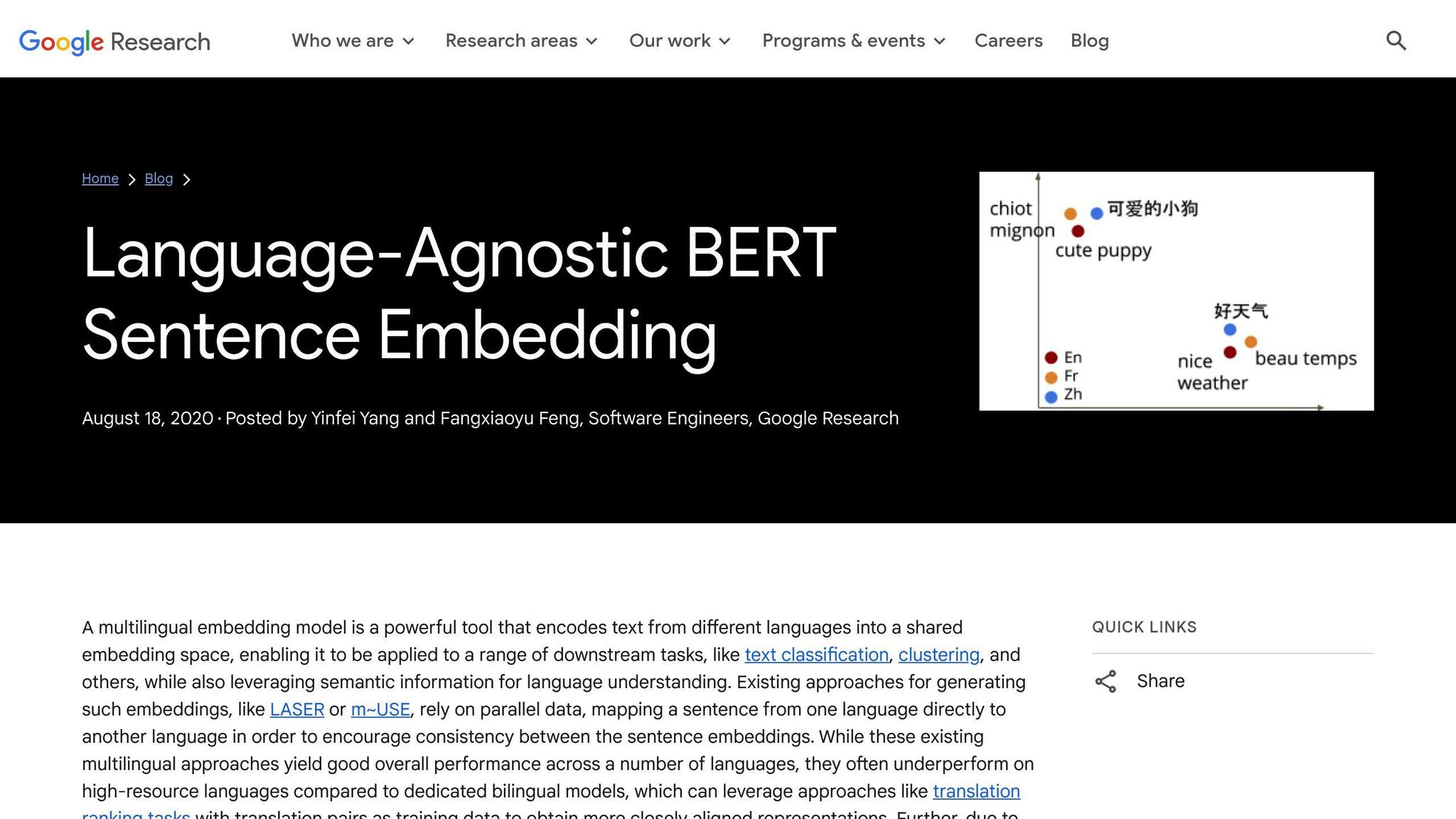
LaBSE is a game-changer for global businesses. It’s a tool that helps understand customer intent across languages. How? By creating sentence embeddings that line up, no matter what language you’re using.
Here’s the scoop on LaBSE:
- It uses a shared transformer encoder for 109 languages
- Outputs a 768-dimensional vector for each sentence
- Trained on a MASSIVE dataset: 17 billion monolingual and 6 billion bilingual sentence pairs
The cool part? LaBSE works well even for languages it hasn’t seen before. It scored 83.7% accuracy on the Tatoeba dataset, beating out LASER’s 65.5%.
Check out how LaBSE stacks up:
| Model | 14 Languages | 36 Languages | 82 Languages | All Languages |
|---|---|---|---|---|
| LaBSE | 95.3% | 95.0% | 87.3% | 83.7% |
| LASER | 95.3% | 84.4% | 75.9% | 65.5% |
LaBSE keeps its high accuracy, even with more languages thrown in.
So, what can you do with LaBSE?
- Search across languages
- Cluster multilingual text
- Spot paraphrases
- Evaluate machine translations
Imagine processing customer queries in Chinese and German from CommonCrawl data (that’s 560 million Chinese and 330 million German sentences) to find translation pairs and get the gist across languages.
The best part? LaBSE is easy to use. You can grab it from TensorFlow Hub and plug it into Keras without breaking a sweat.
But heads up: LaBSE is a big model with nearly half a billion parameters. If you’re tight on computing power, that’s something to keep in mind.
2. Cross-Language Transfer Learning
Cross-language transfer learning is a big deal for intent detection in multiple languages. It lets models trained in one language work well in others, even without extra training data.
Here’s the gist:
- Train on a big English dataset
- Fine-tune on a smaller target language dataset
- The model applies its knowledge to the new language
Real-world examples:
Google Translate used this to add new languages fast. They built accurate translations for languages with little data by using existing models.
XLM-R, a model pre-trained on 100 languages, shows how powerful this can be:
| Metric | XLM-R Performance |
|---|---|
| XNLI Average Accuracy | 83.6% |
| Cross-lingual Transfer Accuracy | 80.9% |
| Improvement over XLM-100 | +10.2% |
| Improvement over mBERT | +14.6% |
These numbers show XLM-R works well across languages, even without specific training.
How to use it:
- Chatbots: Build one model for multiple languages
- Low-resource languages: Use models from data-rich languages to boost performance
A study on European languages showed good results:
| Target Language | Accuracy Using English Dataset |
|---|---|
| German | 83.1% |
| French | 82.9% |
| Lithuanian | 85.3% |
| Latvian | 83.1% |
| Portuguese | 81.3% |
These scores are close to single-language models, proving cross-lingual methods work.
Quick Tips:
- Start with pre-trained multilingual models (mBERT, XLM-R, mT5)
- Fine-tune on your target language data
- Try back-translation for languages with little data
3. Zero-Shot Learning with Large Language Models
LLMs have revolutionized cross-lingual intent detection. They can classify user intents without language-specific training.
How it works:
- LLMs compare user input to intent labels
- They rank labels by relevance
- No language-specific training needed
Banking example:
| User Input | Top Intent Labels (Relevance Score) |
|---|---|
| "I want to close my savings account" | 1. Savings (0.564) 2. Close (0.295) 3. Accounts (0.122) |
This shows LLMs grasping intent across languages effortlessly.
Benefits:
- Easier model deployment
- One model, multiple intents
- Works for less common languages
But LLMs aren’t perfect. A study comparing GPT-4 to fine-tuned BERT models found:
| Task | GPT-4 Performance |
|---|---|
| Simple 7-class classification (ISEAR dataset) | Slightly better than BERT |
| Complex multi-label classification (SemEval, GoEmotions datasets) | Struggled |
| Valence regression | Outperformed BERT significantly |
So, LLMs shine at broad intent detection but might stumble with nuanced tasks.
Want to try zero-shot learning? Here’s how:
- Use pre-trained multilingual models (GPT-4, FLAN-T5)
- Set up with HuggingFace🤗 library
- Test across languages and intents
- Fine-tune for complex tasks if needed
sbb-itb-58cc2bf
4. Machine Translation-Based Approaches
MT is a game-changer for cross-lingual intent detection. It lets you understand user intents across languages without building separate models for each one.
Here’s the basic process:
- Translate user input to a primary language
- Detect intent in the translated text
- Map the intent back to the original language
Thanks to Neural Machine Translation (NMT), this approach has taken off. NMT uses neural networks to learn translation patterns from big datasets, unlike older rule-based systems.
Google’s Neural Machine Translation (GNMT) was a big deal when it launched in 2016. It fixed word order issues and improved lexicon and grammar. Now it supports 109 languages, making it a powerhouse for cross-lingual apps.
A study using the MInDS-14 dataset (14 intents, 14 languages, banking domain) showed some impressive results:
| Scenario | Accuracy Range |
|---|---|
| Translate-to-English | 95%+ for major languages |
| Target-only | 93-97% across languages |
| Multilingual | 81-97% across languages |
These numbers show that MT-based approaches work well, especially when paired with top-notch sentence encoders like LaBSE.
But it’s not all smooth sailing. MT-based methods have some hurdles:
- Translation errors can mess up classification
- Nuances and context might get lost
- Performance can vary between language pairs
To tackle these issues, researchers are trying hybrid approaches. For example, mixing MT with few-shot learning can boost performance, especially for languages with less data.
"Artificially increasing the training set size can improve these models’ accuracy", says a recent study on multilingual intent classification.
This lets developers use existing datasets from data-rich languages to improve performance across all supported languages.
Want to implement MT-based cross-lingual intent detection? Here’s a quick guide:
- Pick a solid NMT system (like Google’s GNMT)
- Choose a primary language for intent processing
- Set up translation pre-processing and post-processing
- Fine-tune with domain-specific data when possible
- Consider hybrid approaches for better accuracy
As NMT keeps improving, we’ll likely see even better cross-lingual intent detection systems down the road.
5. Hybrid Models: Combining Generative and Retrieval Methods
Hybrid models in cross-lingual intent detection mix generative AI with retrieval techniques. This combo boosts accuracy and relevance across languages.
Here’s how it works:
Retrieval-Augmented Generation (RAG) is the key. It lets large language models use extra data without retraining. How? By tapping into knowledge bases built from an organization’s data.
The result? Answers that are timely, context-rich, and go beyond what the model alone can offer.
It’s a two-step process:
- Retrieval: Grabs relevant info from a knowledge base
- Generation: Creates responses using the retrieved data
This approach works well in real-world apps. For example, Cohere‘s vacation rental chatbot gives facts about beach access and nearby spots, all based on current info.
Oracle‘s exploring some interesting use cases too:
- Analyzing financial reports
- Finding oil and gas deposits
- Searching medical databases for key research
Let’s look at the numbers. Hybrid models are performing well:
| Approach | Intent Accuracy | Slot F1 Score |
|---|---|---|
| Single-task | Baseline | Baseline |
| Hybrid (MLMT) | +2% | +3% |
The multilingual multi-task (MLMT) framework is the star here. It uses a shared encoder for multiple languages, capturing subtle details across related languages.
Want to improve your cross-lingual intent detection? Try these:
- Combine generative and retrieval methods
- Use vector databases for quick data coding and searches
- Focus on high-quality, diverse training data
- Keep your knowledge bases updated
The key is balance. You want the flexibility of generative AI with the accuracy of retrieval methods.
Strengths and Weaknesses
Let’s break down the pros and cons of cross-lingual intent detection methods:
| Method | Pros | Cons |
|---|---|---|
| Multilingual Sentence Encoders (LaBSE) | – Works well for less common languages – Good at zero-shot tasks |
– Needs lots of computing power – Struggles with complex tasks |
| Cross-Language Transfer Learning | – Uses knowledge from major languages – Boosts performance for minor languages |
– Results vary based on language similarity – Misses language-specific details |
| Zero-Shot Learning with Large Language Models | – No task-specific training data needed – Handles many intents |
– Limited to 5-8 classes without fine-tuning – Not great for complex or niche tasks |
| Machine Translation-Based Approaches | – Uses existing translation models – Works with any language pair |
– Translation errors affect accuracy – Too slow for real-time use |
| Hybrid Models | – Combines benefits of multiple methods – More accurate and relevant |
– Harder to set up and manage – May feel inconsistent to users |
Your choice depends on your needs and resources. Flan-T5 models, for example, are great at intent classification.
"Recent progress is mostly in data handling, not architecture. This shows small language models work well for many tasks", says AI researcher Serj Smorodinsky.
This means smaller, efficient models can work for cross-lingual intent detection.
When implementing:
- Weigh model size against performance. Smaller models like Flan-T5-Base (751,054 downloads in April 2024) can be more cost-effective.
- For zero-shot tasks, fine-tuned Flan-T5 can handle up to 20 classes in one prompt.
- Hybrid approaches, though complex, can boost accuracy. Combining retrieval-augmented generation (RAG) with intent classification models can improve real-world performance.
- For less common languages, cross-language transfer learning or multilingual sentence encoders might work better than just large language models.
- For quick responses, consider each method’s computing needs. Machine translation-based approaches, while versatile, might be too slow for real-time use.
Summary
Cross-lingual intent detection has come a long way in 2024. Here’s a snapshot of the top methods:
| Method | Pro | Con |
|---|---|---|
| Multilingual Sentence Encoders (LaBSE) | Covers 109 languages | Resource-hungry |
| Cross-Language Transfer Learning | Helps minor languages | Results vary |
| Zero-Shot Learning with LLMs | No task-specific data needed | Limited classes |
| Machine Translation-Based | Works with any language pair | Not real-time |
| Hybrid Models | More accurate | Complex setup |
The Cohere multilingual embedding model is a standout. It hits 69.7% accuracy for non-English languages with just 50 examples per class, beating others by up to 10 points.
For businesses, intent classification is crucial. It’s the key to understanding customer needs and boosting service quality. Here’s a fact: 70% of customers would recommend a brand after a good experience.
Choosing the right method? It’s all about your needs and resources. Smaller models like Flan-T5-Base can be cost-effective for many tasks. For less common languages, cross-language transfer learning or multilingual sentence encoders might be your best bet.


